LJについて
LJ (Latinized Japanese/Latin字日本語) についての詳細。
(※「言語に関する取り組み」全般については → 言語について)
(※ 本項の内容 (LJ) を含むEnglish習得法「RV-CJ (RJ) method」全般については → English Way)
はじめに
「Latin字のみ表記の日本語」としての「LJ」
まずは、LJ (Latinized Japanese/Latin字日本語) の必要性について、述べていきましょう。
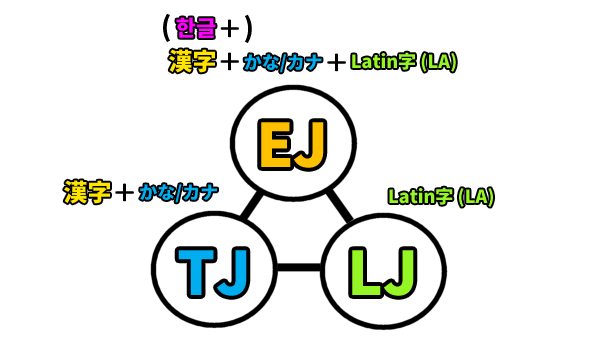
「漢字+かな/カナ+Latin字」の併用で表記するEJに加えて、欧米その他の多くの地域の言語と同じく、「Latin字のみ」で表記するLJという表記optionを持っておくことは、日本語の、ひいては日本の社会/文化/文明としての可能性を広げて、発展を後押しする効果が期待されます。
「Latin字のみ」で表記するという表記optionには、単に、
- 「世界の多数派である「Latin字圏 (LA Club)」への仲間入り」ができ、様々な便益/融通/言語的文化的拡張性が得られる。
という利点だけではなく、加えて、
- 「漢字表記/漢字変換」の手間から、解放される。
- 「Latin字特有の省略表記」を、活用できる。
という利点も、あります。

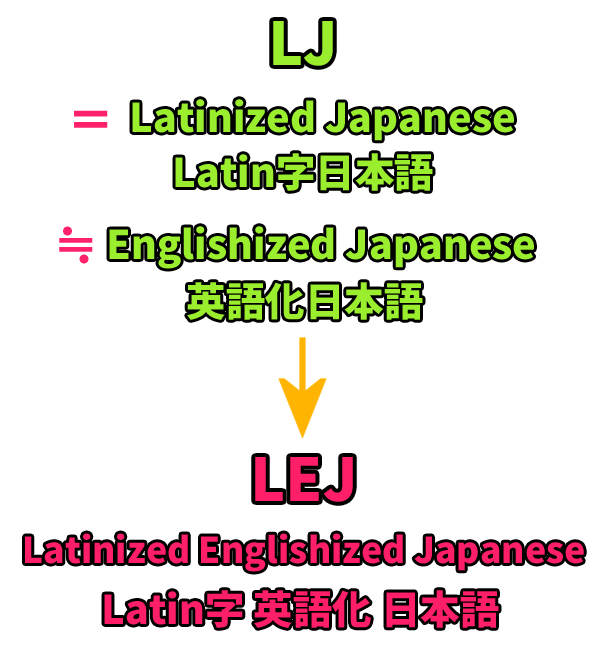
「別名/異称」としての「LEJ」
そんな諸々の「Latin字表記使用の利点」の中でも、その最たるものは、
- 事実上 (de facto) の世界共通語として機能しているEnglishの語彙/表現を、直接輸入/利用し易くなる
という点であり、LJではまさしく、そうしたEnglishの語彙/表現の「積極的な輸入/使用」が推奨されますし、それ故に、このLJは、
- EJ (Englishized Japanese/英語化日本語)
といった呼び方もできる訳ですが、これだと、EJ (拡張日本語) と紛らわしいので、そうした性格を表現したい場合は、LJと組み合わせて、
- LEJ (Latinized Englishized Japanese/Latin字 英語化 日本語)
と表現してもらうと、良いでしょう。
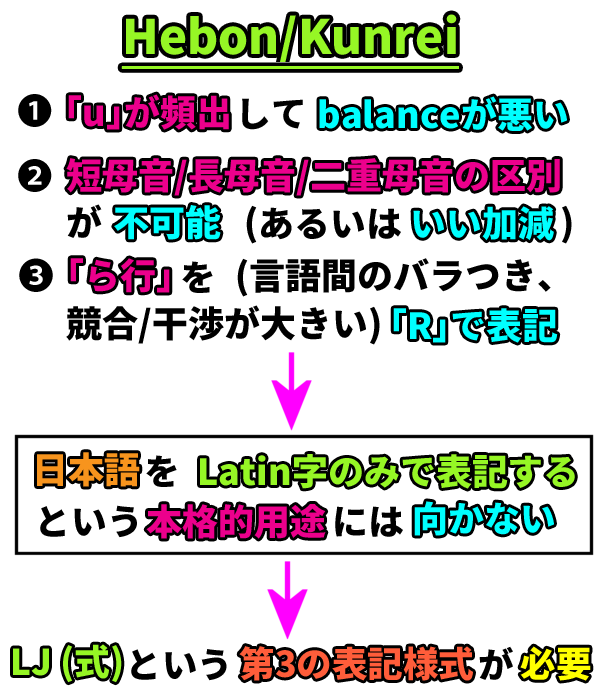
「第3のLatin字表記様式」としての「LJ式」
ただし、既存の「Hebon/Hepburn (ヘボン) 式」や「訓令式」といったLatin字表記様式は、
- ◾️① 50音の「う段」の音に機械的に「-u」表記を割り振っているため、(他言語のLatin字表記と比べて)「u」が不自然に頻出してしまう。
- (※ 例えば、「桝を美しく塗る」は「masu o utsukushiku nuru」といった具合になる。)
- ◾️② 日本語の語彙区別において非常に重要な、「短母音/長母音/二重母音の区別/書き分け」が、不可能、あるいは雑/いい加減。
- (※ 例えば、代表的な /ou/ の表記で言えば、Hebon式では「o」「ō」、訓令式では「ô」、さらに人名表記で用いられる例外/慣用表記として「ou」「oh」といった表記も用いられ、混在している。同じく代表的な /uː/ の表記で言えば、Hebon式では「u」「ū」、訓令式では「û」、例外/慣用表記として「uu」といった表記が用いられ、混在している。)
- ◾️③ 「ら行」の音が、言語による音のバラつきが極めて小さく、他言語 (や、そこからの借用語) との音の競合/干渉が無い「L」ではなく、言語による音のバラつきが極めて大きく、癖の強い「R」を用いて表記されてしまっている。
- (※ 例えば、「r」は世界一般的には「巻き舌 (震え音)」の音だが、西欧系言語では特殊な発音が多く、American Englishでは「そり舌」、一部のFrench/Germanでは「口蓋垂 (のどひこ/のどちんこ) を使った震え音」、また一部のFrench/Portugueseでは「口蓋垂を使った摩擦音 (「は行」のような音)」だったりする。)
といった欠点があるため、LJの用途には不向きです。そこで、下述するように、上記の欠点を無くした、LJ専用の「第3」のLatin字表記様式である「LJ式」を、新たに用意する必要があります。
- 1. Hebon-shiki
- 2. Kunrei-shiki
- 3. LJ-shiki ← New!!
ただし、もう少し厳密に言うと、いきなり「LJ式」のような不慣れな様式を使用するのは大変でしょうから、その前段階、中間的な様式として、上記の③の部分のみを修正した、すなわち、
- 「ら行」の音を、(「R」ではなく)「L」で表記する
(また、冗長な「u」は、適度に間引く)
という最小限の変化のみを (基本的にはHebon式に) 加えた様式、これをここでは「L式」と呼びますが、これにまずは慣れてもらうと良いでしょう。
(※ この「「ら行」の音を「L」で表記する」(+「適度に「u」を間引く」) 程度の変化であれば、ChatGPTのようなAIも、(通常のHebon式と同じように) 日本語として問題無く理解/反応してくれます。(確認済み))
(※ また、(母音を省略するなどの) Shortening (短縮) 表記においては、この「L式」と「LJ式」は一致することになるので、そういった意味でも、この「L式」は、橋渡し的な様式として最適だと言えます。)
- 1. Hebon-shiki
- 2. Kunrei-shiki
- (3. L-shiki ← New!!)
- 4. LJ-shiki ← New!!

基本
50音表
| 行\段 | あ | い | う | え | お |
|---|---|---|---|---|---|
| あ行 | a | i | u | e | o |
| か行 | ka | ki | ku/k | ke | ko |
| が行 | ga | gi | gu/g | ge | go |
| さ行 | sa | si (ši/sh) (Kanji: shi) |
su/s | se | so |
| ざ行 | za | zi (ži/zh) (Kanji: ji) |
zu/z | ze | zo |
| しゃ行 | sha | shu | sho | ||
| (じゃ行) | (zha) | (zhu) | (zho) | ||
| た行 | ta | ti (ťi/č/ch) (Kanji: chi/-ch) |
tsu/ts | te | to |
| だ行 | da | (di (ďi/j)) | (dzu/dz) | de | do |
| ちゃ行 | cha | chu | cho | ||
| じゃ行/ぢゃ行 | ja | ju | jo | ||
| は行 | ha | hi | hu | he | ho |
| ぱ行 | pa | pi | pu/p | pe | po |
| ば行 | ba | bi | bu/b | be | bo |
| ら行 | la | li | lu/l | le | lo |
| ま行 | ma | mi | mu/m | me | mo |
| な行 | na | ni | nu/n | ne | no |
| や行 | ya | yu | yo | ||
| わ行 | wa | wo/o | |||
| n' (m/n) | |||||
| -う | aw | iw | uw | - | ow |
表記規則
LJの主な特徴/表記規則は、以下の通りです。
- (1) 「u」を取り除いた「子音単独」の表記も認める。
(例) taskel, -des/-mas
— 表記の冗長性排除と発音との一致性向上のため。* - (2) 「し」「じ」「ち」は、固有語と漢字語で表記を変える。
(例) 固有語 : si (sh), zi (zh), ti (ch)、漢字語 : shi, ji, chi(-ch)
— 形容詞/動詞活用における表記整合性/簡便性などのため。** - (3) 「ら行」を、「L」で表記する。
(例) la, li, lu/l, le, lo
— 「R」は、言語による音のバラつきが極めて大きいため。*** - (4) 二重母音/長母音の後部の「う」を、「w」で表記する。
(例) aw, iw, uw, ow
— 日本語の音韻/活用との相性や、視認性/分別性向上のため。****

(* 「u」除去 (U elimination) の基準に関しては、
- 活用語尾の直前の「u」は、残す。
- 連続する前後の音節で、「u」が重複しないようにする。
- 漢字語の場合、「一文字一音節(一母音)」の原則 (「-ki」を除く) を守る。(※詳細は下述)
という3つの原則を踏まえておけば、ほとんどの場合、自ずと表記の形は導けます。)
(** こうしておかないと、「さ行」「た行」の動詞活用において、
- 「sa/shi/s(u)/se」
- 「ta/chi/ts(u)/te」
といった、一貫性/統一性の無い表記を用いなければならなくなってしまいます。
また逆に、「訓令式」風の「si」「ti」表記のみに統一してしまうと、今度は漢字語の表記としてイマイチになってしまいます。そこで、両者の使い分けが一番望ましいという結論に至りました。
なお、50音表にも示されているように、(特に形容詞/動詞(用言)以外の-) 固有語表記において、「し」「じ」「ち」が「歯茎硬口蓋音」であることを表記に反映して表現したい (そうじゃないと感覚的に気持ち悪い-) という場合は、「sh」「zh」「ch」という表記も許容します。その辺りは柔軟に対処してもらうといいでしょう。)
(*** 「巻き舌」「反り舌」「のどひこ」等々。
したがって、そうした各言語の (借用語の-)「R音」との競合/干渉を避けるためには、「ら行」を「L」で表記するのが望ましい。)
(**** こうしておくと、例えば、「言う」(iw) 等の活用で、
- iw(言う) → iwanai(言わない)
といった連続性のある円滑な表記ができるようになりますし、「う」の長音表現としても、
- 1. 入力環境が制限される「ū」「û」
- 2. 見た目が冗長な「uu」
- 3. 上記2つの問題を抱えていない、「LJ式」の「uw」
といった具合に、より容易かつ明解な、優れた表記になります。)

補足
「u」の補充
既述の通り、「LJ式」では、表記の冗長性を無くすために、不要な「u」の除去を推奨しています。
しかし、実際問題、「動詞の終止形」を中心に、
- 「語末の「u」があった方が、音としての収まりが良い/自然」
という場合も多々ありますし、特に、そうした語彙が「文末」に来る場合や、「歌の歌詞」などで「音を伸ばす(歌い上げる)」ような箇所の語彙などでは、語末の「u」が省かれると、「語調/音調」「音の座り/落ち着き」が良くない場合が、少なくありません。
あるいは、新出の (自分や相手が不慣れな) 言葉を確認/強調するために、「一音一音、はっきり明確に発音」したい場合なども、時にはあります。
そこで、そうした「u」があった方がいい場合には、普段/通常は「u」を省いていても、
- 「そこだけ (「音声的」にも、「表記的」にも) 一時的/臨時的に、「u」を挿入/補充していい」
ものとします。こうした措置を、ここでは、
- 「u」補充 (U complement)
と呼びます。
(※もちろん、「sh」「ch」の後などは、「u」ではなく、
- 「i」補充 (I complement)
になります。)

補充する「u」は、そのままただの「u」でもいいわけですが、補充されたものであることを強調したい場合は、丸括弧付きで「(u)」と表記しておくと、分かりやすいでしょう。
「LJ式」の表記は、こうした柔軟性も兼ね備えているのだということを、併せて覚えておいてもらいたいと思います。

漢字音と音節
また、漢字音の表記に関しては、漢字文化圏のstandardに合わせ、
- 「漢字1文字=1音節」の原則
を守ることが、望ましいです (「-ki」は除く)。
ここで言う「音節」とは、
- 「子音(頭子音) – 母音 – 子音(末子音)」(CVC)
の範囲のことです。
日本以外の漢字文化圏では、全ての漢字音がこの範囲に収まる「漢字1文字=1音節」の原則が成り立っているわけですが、日本語の「ヘボン式」「訓令式」では、全ての音に母音を機械的/強制的に割り振るため、例えば「gaku」(学)、「hatsu」(発)、「tachi」(達)といったように、末子音に母音u/iが付属されて2音節になってしまい、この原則が成り立って来ませんでした。
しかし、余分なu/iを省くことが可能な「LJ式」では、「gak」(学)、「hats」(発)、「tach」(達)といったように、語末のu/iを省いて、漢字文化圏のstandardである「漢字1文字=1音節」の原則を成立/回復させることが可能になるので、こうした表記を心がけてもらいたいと思います。
(※ただし、「shiki」(式)、「teki」(的)といった「-ki」の音に関しては、語末の母音iを省いてしまうと、現時点では語彙の音声的な同一性の識別に支障を来すので、例外的にこのままでいいとします。他方で同時に、母音iを省いて「shik」(式)、「tek」(的)としても、間違いではないこととします。将来的には後者の音/表記の浸透を待って、そちらに統合していくのが望ましいでしょう。)
なお、「LJ式」表記の漢字音一覧は、こちらのwiki pageにまとめてあるので、参照してもらうといいでしょう。

その他 (助詞など)
また、助詞の「は」「を」の表記に関しては、「wa」「wo」だと、(繰り返しの使用や、他の助詞との組み合わせ等を考えると-) 冗長で煩わしいので、「a」「o」を推奨します。
(※その他の助詞/助動詞類、用言の活用などに関しては、こちらのwiki pagesにまとめてあるので、参照してもらうといいでしょう。)
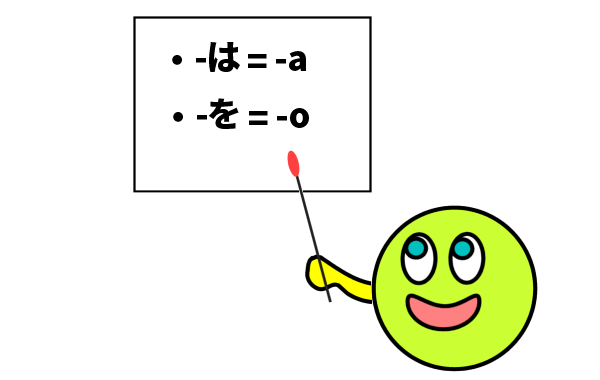
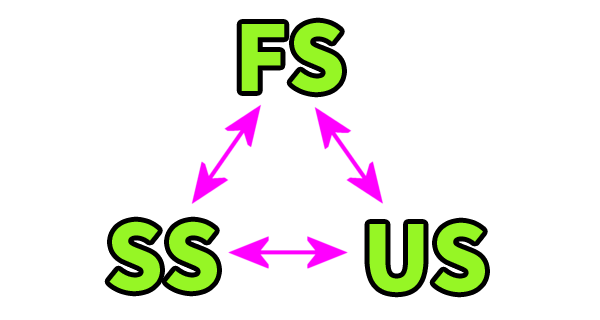
hyphen(-)/spaceと3つのstyles
この「LJ式」で実際に日本語を表記していく場合、
- 「Formal Style」(FS/正式表記) — 助詞や語尾/助動詞などを、hyphen(ハイフン)でつなげた表記。
- 「Simple Style」(SS/簡略表記) — それを省いた表記。
- 「United Style」(US/統合表記) — 助詞や語尾/助動詞などを、結合させた表記。
という、3通りの異なる書き方が、考えられます。
試しに、これらを比較すると、このようになります。
- Tamesini kolela-o hikak-sul-to kono yow-ni nalimas. 【FS】
- Tamesini kolela o hikak sul to kono yowni nalimas. 【SS】
- Tamesini kolelao hikaksulto konoyowni nalimas. 【US】

hyphen(ハイフン)を用いる「FS」は、日本語の構造が分かりやすく、見た目にも「締まりのある」表記になる一方で、やや表記/入力に手間がかかります。
それに対して、「SS」は、hyphen(ハイフン)を用いない分、表記/入力が手っ取り早くなりますが、その分日本語の構造が見えづらくなってしまうという欠点があります。
「US」も、hyphen(ハイフン)を用いない分、表記/入力が手っ取り早くなりますし、「SS」と比べて日本語の構造も見えやすいですが、spaceを用いずに語をつなげている分、単語の識別がしづらくなってしまいます。
「LJ式」で日本語を表記する際には、この3つの異なる表記法を、必要/用途に応じて、かしこく使い分けて行ってもらうといいでしょう。
apostrophe(')の挿入
また、これは「LJ式」に限った話ではありませんが、「音節末子音+母音」の組み合わせで、視認性や発音に支障を来しそうな場合は、apostrophe(アポストロフィ)「’」を挿入することを推奨します。
従来の「ヘボン式」「訓令式」でも、「ん+半母音(y)/母音(a/i/u/e/o)」の組み合わせで、
- 「三洋」(サンヨー) : Sanyo → San’yo
- 「純一郎」(じゅんいちろう) : Junichiro → Jun’ichiro
といった具合に、apostrophe「’」を挿入すべき事例は散見されたわけですが、「LJ式」の場合、これに加え、上記した (あるいは下述する-) ように、漢字音の語末の不要な母音を排除するため、
- 「録音」(ろくおん) : lokon → lok’on
- 「発案」(はつあん) : hatsan → hats’an
といったように、漢字熟語の「末子音+母音」でも、こうした事例が発生します。
こうした漢字熟語の表記に関しては、あくまでも慣れの問題であり、apostrophe「’」を挿入しなくても別に構わないと言えば構わないわけですが、不慣れな人がつっかからないようにするための配慮として、こうしたことも頭の片隅に入れておいてもらうといいでしょう。

高低accentの表記
また、日本語には高低accentがあり、例えば、
- 端 (はし)
- 箸 (↑はし)
- 橋 (は↑し)
のように、それによって語彙を区別している面もあります。
多くの日本人はこうしたことを、あまり意識せずに行っていますが、例えば、(方言がきつい地域の) 地方出身者や、外国(人)の日本語学習者のために、こうした高音部分を表現できる「表記option」があると、便利だと思います。
従来のかな/カナでは、なかなかそうした表現は難しかった訳ですが、LJのようなLatinjiの場合は、(á/í/ú/é/óといった) 「accent記号付き母音字」をそのまま転用すれば良いだけなので、簡単です。
例えば、上記の例で言えば、
- 端 (はし/hasi)
- 箸 (↑はし/hási)
- 橋 (は↑し/hasí)
と、なります。
こうしたLatinji表記の利点についても、頭の片隅に入れておいてもらうと良いでしょう。

山括弧 < > の推奨
また、これは好みの問題でもありますが、Englishなどでは、会話や強調の表現に、専ら点型の引用符 " " が用いられていますが、鍵括弧「」に慣れている日本人の場合、この引用符が感覚的にしっくり来ない人も結構多いと思います。
そこでLJでは、それらの用途に関して、点型の引用符 " " の代わりに、鍵括弧「」に近い山括弧 < > の使用を推奨します。これはFrench (フランス語) に近い形ですね。

地名/人名とHebon式/English式
なお、この「LJ式」で、実際に日本語を表記していくと、とある1つの問題が出て来ます。
それは、「日本の人名/地名/組織名/文化事象名」等の語彙の表記 (綴り) が、旧来の「ヘボン式」と、「LJ式」との間で衝突/混乱してしまうという点です。
そこで、この点に関しては、とりあえず「LJ」が普及/定着するまでの暫定的な措置として、
- 「日本の人名/地名」等に関しては、旧来の「ヘボン式」表記を認める
という特例を設けています。
「自分の名前だけはどうしても「LJ式」で書きたい、そうしないと気持ち悪い」といったこだわり派は、(行政手続き/契約手続きなど、形式が限定されている場合はともかくとして) 自分の名前だけは「LJ式」で書くようにすればいいでしょうし、他の「日本の人名/地名」等に関しては、当面は「ヘボン式」で表記しておくのが無難でしょう。

また、これは完全に趣味/お遊びの領域の話ですが、何かしらの活動をするに当たり、何らかの活動名、すなわちnickname、pen name、alias、pseudonymの類を作る際に、glabalな活動を考えるのであれば、香港人や韓国人が自分達の人名にやっているように、母音表記をEnglish風に、すなわち、
- い/いい (イ/イー) : (y)ee
- う/うう (ウ/ウー) : (w)oo
- えい (エイ) : a, ae, ai, ay
- あい (アイ) : i, y
といった表記を用いると、比較的馴染み易く、認知され易くなります。
また、これは「Englishとの親和性を高めること」という、LJの主目的とも、合致します。
したがって、こういった遊び心ある軽快な名前文化も、LJでは併せて広めて行きたい、普及/促進させて行きたいと、考えています。

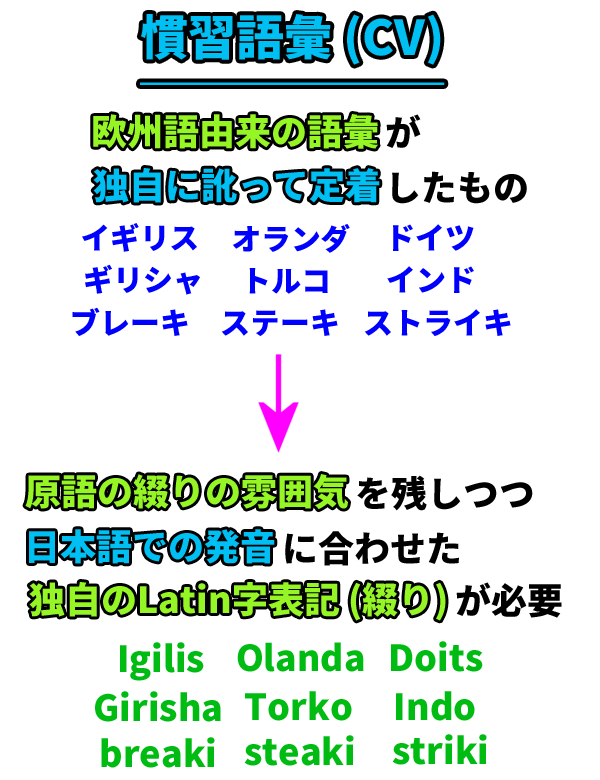
慣習語彙 (CV) の扱い
これはLJのみならず、EJにも共通して言えることですが、日本語には、
- English等の欧州語由来の語彙でありながら、独自に訛って定着した語彙
というものが、それなりにあります。
例えば、イギリス、オランダ、ドイツ、ギリシャ、トルコ、インドといった地名/国名や、ブレーキ、ステーキ、ストライキといった最後にiを補った語彙などが、代表的な例です。
こうした語彙を、ここでは、
- 慣習語彙 (Conventional Vocabulary/CV)
と呼ぶことにしますが、こうした慣習語彙 (CV) は、原語の綴りでLatin字表記すると、日本語での発音とズレてしまいますし、逆に「ヘボン式」や「LJ式」で機械的/画一的に表記すると、元々の語彙の雰囲気/感覚が失われてしまうことが多いので、そのどちらでもない、
- 原語の綴りの雰囲気を残しつつ、日本語での発音に合わせた、独自のLatin字表記 (綴り)
といったものを、別個に用意することが推奨されます。
(※ 面倒な場合は、「ヘボン式」でも構いません。)
先に挙げた例で言えば、Igilis、Olanda、Doits、Girisha、Torko、Indoや、breaki、steaki、strikiといった具合になります。
こうした表記 (綴り) は、語彙ごとに個別に設定/定着/普及を図っていく必要がありますが、とりあえずはこういったものもあるのだということだけでも、頭の片隅に入れておいてもらいたいと思います。
漢字/仮名の混合/併記
また、日本語の「Latin字表記」では、当然のことながら、それなりの量の同音異義語が発生することになるので、それらを用いる場合や、また、不慣れ/難解な語彙を用いる場合などもそうですが、時折、漢字/仮名を用いて、視覚的に識別/説明できるようにしたくなる場面も、出てくると思います。
そこで、「LJ」では、そうした必要に応じた漢字/仮名の (括弧書きを用いた) 併記や、部分的な漢字/仮名への置き換えも、認めています。
したがって、「LJ」においては、その種の同音異義語の識別にまつわる心配を、する必要はありません。

ShorteningとEnglishization
日本語の「Latin字表記」は、必ずしも良いことばかりではありません。主な問題として、
- (1) 表記が、長くなる。
(漢字と仮名(かな/カナ)によって圧縮されていた部分が、無くなる。) - (2) 同音異義語が、多くなる。
(漢字と仮名(かな/カナ)によって書き分けられていた同音異義語である漢字語/固有語の多くが、書き分けられなくなる。)
の2点を、挙げることができます。
したがって、この2つの問題に対して、
- (1) 各種の「短縮表記」を積極的に導入/活用して、表記を圧縮する。
— 「Shortening」(短縮)【S】 - (2) English Vocabulary(英語語彙)を積極的に導入/活用して、同音異義語の使用機会を減らす。
— 「Englishization」(英語化)【E】
という改善措置を、それぞれ講じる必要があります。
これによって、日本語の「Latin字表記」は、従来の「漢字/仮名表記」に劣らない、むしろそれを超越した実用性を獲得できます。

日本語の「Latin字表記」における、「Shortening」(短縮)の種類としては、以下のようなものが考えられます。
- 1. Abbreviation (AB)
- 1. Cutting/Contraction (C) — cof (←coffee)など。
- 2. Initialism (I) — USA, DNAなど。
- 3. Acronym (AC) — NATO, AIDSなど。
- 2. Abjad style (AJ)/Consonant extraction (CE)
- 1. Normal — sst (←sosite)など。
- 2. (Kanji-shortening style (KJ) — bk (←benkyow), kg (←kokgo)など。)
- 3. (Predicate-shortening style (P) — -ni (← -naio ikenai)など。)
- 3. Kana-shortening style (K) — miniska (←mini skirt)など。
- → Kana-super-shortening style (K2/SS) — mis (←miniska/mini skirt)など。
1は、現在のEnglishでも普通に用いられている類のものであり、珍しいものでありません (1-1は、Englishの場合は、period(.)を付けて省略を表現するのが常ですが)。
2は、ちょうどArabic(アラビア語)/Hebrew(ヘブライ語)などの中東言語にも見られるような、子音のみ (音節が母音で始まる場合や、二重母音/長母音の末母音を表す場合などは、母音字も含む) で簡略表記する手法ですね。日本語との相性も良いので、日本語のLatinization(Latin字化)表記においては、この手法がmain(メイン)になると言っていいでしょう。
(※なお、こうした「母音を省略する簡略表記法」は、Englishなど他の言語にも適用可能です。Englishに適用した場合、それは「Abjad English」(AE)とでも呼ぶべきものになるでしょう。)
2-2は、漢字語のみに使用可能な手法であり、漢字単位での頭文字を表記する手法です。音節の末子音を表記しない分だけ、Abjad style(AJ)よりも圧縮度が高くなっています。ただし、末子音も表記するAbjad style(AJ)の方が、「二字熟語」等の短い漢字語の識別には有利なので、漢字語も基本的にはAbjad style(AJ)で構わないですし、このKanji style(KJ)は、「四字熟語」等の長ったらしい漢字語や、比較的識別しやすい漢字語に、限定して使用するといいでしょう。
2-3は、長ったらしい述部の定形表現を、語句単位で圧縮したものです。圧縮度が極めて高いので、初見では戸惑うかもしれませんが、慣れればとても便利です。
3は、かな/カナの語感に沿って、「ひらがな略語」「カタカナ略語」をそのままLatinize(Latin字化)したものです。
通常の省略方式(K)に加えて、特に商業的に都合が良いように、「言い易さ」と「新鮮さ」を追求し、より極端に言葉を圧縮する方式(K2/SS)も、あります。
これらの内、特に、2のAbjad style(AJ) /Consonant extraction(CE)が果たす役割は、とても大きなものとなります。
このAbjad style(AJ)/Consonant extraction(CE)によって、助詞/助動詞/接続詞といった頻繁に用いられる構造的な語彙の表記を圧縮するだけでも、日本語のLatin字表記は、かなり圧縮/簡素化できます。

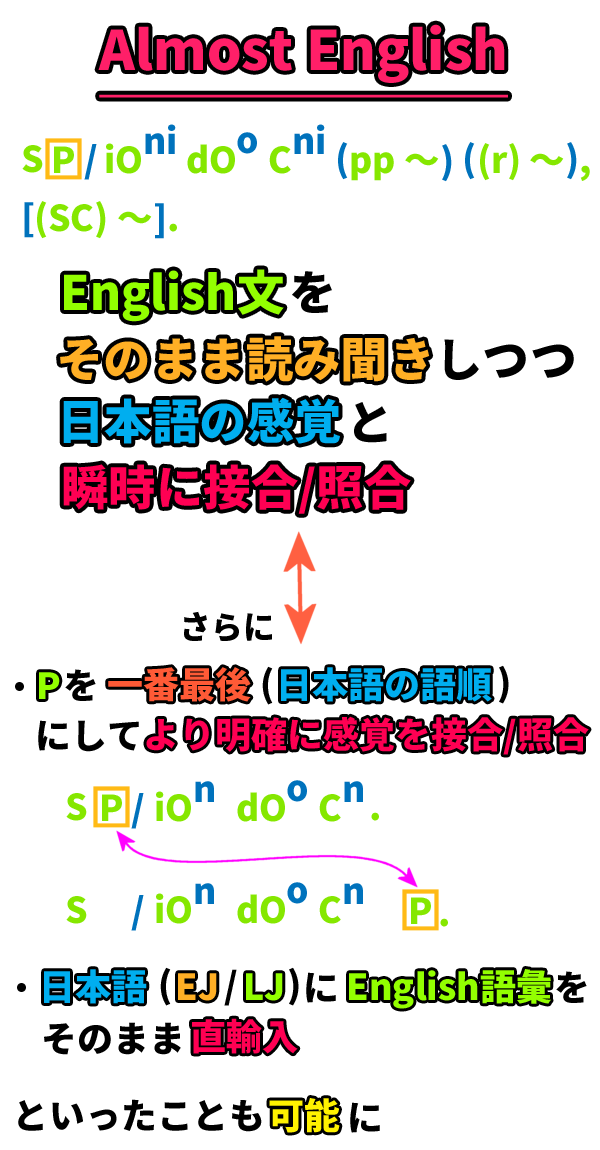
ほぼ英語 (AE) について
AE (Almost English/ほぼ英語) とは、RV-CJ method (RJ method) で導入した概念であり、要するに、EnglishをLJへと変換 (感覚接合) する際に、
- 格助詞は、間接目的語 (iO)/直接目的語 (dO)/補語 (C) へのni/o/niのみ
- (述部 (P) の末尾への移動)
といった「必要最低限の措置」のみ認めるLJの様式のことです。
その点以外の部分は「ほぼ英語そのまま」なので、この名が付きました。
このAEは、通常のLJと比べると、何ともおかしなものに感じるかもしれませんが、これは「NihongoとEnglishをつなぐkey」となるものなので、むしろ通常のLJよりも優先的/頻繁に使用され、「標準化」されるのが望ましいと言えます。
発音表記 (ST) について
なお、「Latin字表記」に伴う問題として、「発音表記問題」がある点は無視できません。
Latin字は、「数多くの言語で採用されている文字」であり、それゆえに、子音でも母音でも、言語間で、「表記/綴り」と「発音」の対応関係に関して、それなりの「差異/ブレ/揺れ/多様性」があります。
更に、Englishの場合などは、同一言語内で、同一文字を、(単語/綴りや、地域/方言ごとに) 様々に異なる多様な発音で、読んだりもします。
したがって、「Latin字表記」を採用すると、「この単語はどのように発音するのか」を迷う場合が、必ずそれなりに出てくることになりますし、その際に用いる、「発音を表記するための、別の表記体系」が、どうしても必要になります。
その際、一般的には「IPA(国際音声字母)」が用いられますが、これはなかなか扱いに手間がかかります。他方、Englishなどでは、様々な独自のLatin字発音表記 (respelling) が用いられたりもしますが、汎用性に欠けますし、日本人にはあまり使い勝手が良くありません。
そこで、「Latin字表記」を提案している立場上、我々は独自の、
- 「汎用性があって、日本人にも使いやすい発音表記」
を、併せて考案/提示しておく責任/義務があると考えますし、ここでそれを紹介しておきたいと思います。
その我々が提案する「発音表記」を、ここでは、
- 「ST式」(Simple Transcription式)
と呼ぶことにします。

その主な仕様は、以下の通りです。
(※具体的な使用例は、LJ Wikiにまとめてあります。)
■ 全般
- // とLatin字を用いて発音を表記。
- accentは、母音字を大文字にして表現。
■ 子音
- [ʃ] [ʒ] は /sh/ /zh/ で表記。
- [tʃ] [dʒ] は /ch/ /j/ で表記。
- [θ] [ð] は /th/ /dh/ で表記。
- [ɲ] は /ny/ で表記。
- [j] は /y/ で表記。
- 米国英語に見られる「flapping」は /R/ /N/ で表記。(※書き分け/強調したい場合。)
- 「そり舌」は /rw/ や /w/、「巻き舌」は /rr/ や /r'/、「のどひこ」は /rx/ や /x/ で表記。(※それぞれの特徴を強調したい場合。)
■ 母音
- /a/ /i/ /u/ /e/ /o/ の5音に加え、中間音は/(ea)/ /(eo)/ /(iu)/ のように括弧を用いて表記。
(※括弧は、状況的/文脈的に省略しても支障無い場合は省略可。また、schwa(シュワー)のような曖昧音は、/*/ のように「*」を用いた簡略表記も可。)- [ə] [ɜ] は /(ua)/ /*/ 等で表記。
- [æ] は /(ea)/ で表記。
- [ʌ] は /(oa)/ で表記。
- 長母音は、/aa/ /ii/ /uu/ /ee/ /oo/ /(uaa)/ /**/ のように、母音字を重複させて表記。
以上で、「発音表記」に関しても万全です。
発音表記 (REK) について
また、「発音表記」に関して、もう1つだけ付け加えておくと、RK (REK) を知っている日本人が対象で、主にEnglishなどの読みに用いるのであれば、RK Wiki でもそうしているように、REKをそのままLatin字化した表記を用いるのが、一番簡単です。

物足りなければ、そこにCK (慣習カタカナ語) のHebon式表記も添えて、「挟み撃ち」にすることもできます。

したがって、我々としては、前項のSTは「補助的/予備的発音表記」とし、こちらのREK (Latinized version) を、「main発音表記」として推奨しておきたいと思います。(※ 専用Wiki → REK (L) Wiki)
人称代名詞について
最後に、完全にオマケのような内容になりますが、人称代名詞についても、少し述べておきたいと思います。
日本語の人称代名詞は、数も多くて使い分けが面倒であり、また他言語と比べて長ったらしいものも少なくありません。
- 一人称 : わたくし、わたし、ぼく、おれ、われ、わがはい...
- 二人称 : あなた、きみ、おまえ、てめえ、きさま...
- 三人称 : 彼/彼女、あいつ...
そこで、どうにかもっと簡単で端的な表現ができないものかと、色々と検討した結果、以下の4種類が実用に耐え得ると考えられるので、ここで述べておきたいと思います。
まず第1に、一番簡単で受容されやすい短縮版として、
- 一人称 : たし/tash (複 : たしら/tashla)
- 二人称 : なた/nata (複 : なたら/natala)
- 三人称 : かれ/kale, かじょ/kajo (複 : かれら/kalela, かじょら/kajola)
- (不定称 : だれ/dale)
といったものを、挙げることができます。
第2に、日本語の古語から導き出せる端的な表現としては、
- 一人称 : わ/wa (複 : わら/wala)
- 二人称 : な/na (複 : なら/nala)
- 三人称 : か/ka (複 : から/kala)
- 不定称 : た/ta
といったものを、挙げることができます。
第3に、English(英語)の人称代名詞を活用するという方法もあります。
この場合、格助詞との組み合わせによって、
- 一人称 : Iが/は (I ga/a)、meを/から/に/へ/と/の (me o/kala/ni/e/to/no)
(複 : weが/は (we ga/a)、usを/から/に/へ/と/の (us o/kala/ni/e/to/no)) - 二人称 : youが/は/を/から/に/へ/と/の (you ga/a/o/kala/ni/e/to/no)
- 三人称 : heが/は (he ga/a)、himを/から/に/と/の (him o/kala/ni/to/no)
sheが/は (she ga/a)、herを/から/に/と/の (her o/kala/ni/to/no)
(複 : theyが/は (they ga/a)、themを/に/と/の (them o/ni/to/no)) - 不定称 : whoが/は (who ga/a)、whomを/に/と/の (whom o/ni/to/no)
といったように、2通りに分かれることが多いので、注意が必要です。
第4に、中国語の人称代名詞、すなわち、
- 一人称 : 我/wo (複 : 我們/women)
- 二人称 : 你/ni (複 : 你們/nimen)
- 三人称 : 他/ta (複 : 他們/tamen)
- 不定称 : 誰/shei
といったものを、挙げることができます。
Englishのような格変化への配慮も必要ありませんし、上記した日本語の古語とも語感が似ていて、日本語との相性も良く、かなり有力な代替案の1つです。
(ちなみに、第5の表記法として、中国語と並ぶもう1つの日本語の兄弟言語、すなわち韓国語 (朝鮮語) の人称代名詞を活用する、という方法もあります。
韓国語の人称代名詞の場合、「助動詞가(が)が後続する場合と、所有格助詞의(の)の意味を内包した結合形の場合に、(同形の)独特の形になる」という、ちょっとしたクセがありますが、兄弟言語である日本語であればこそ、そのクセを乗り越えることが可能です。具体的には、
- 一人称 : 저/cheo-나/na (제/che-내/naeが/(の)) (複 : 우리/uri)
- 二人称 : 당신/tangsin-너(니)/neo(ni) (네/neが/(の)) (複 : 너희(니네)/neohui(nine))
- 三人称 : 그/keu (複 : 그들/keudeul)
- 不定称 : 누구/nugu (누/nuが)
といった形になります。正直、他の選択肢と比べて圧倒的に使い勝手が悪いですし、使える人を選ぶので、あまり推奨はしませんが、とりあえずこんなoptionもあるということを、頭の片隅に入れておいてもらうだけでいいでしょう。)
以上の4つを押さえておいてもらえば、日本語の人称代名詞にまつわる、様々な問題に関しても、上手く対処していけるようになることでしょう。

関連pages
Link(s)
- REK (L) Wiki【一覧】--- 「Latin字版REK」用wiki。
- LJA
- LJ Pedia